
How LLMs Work: Stages 4-6
Intersecting AI #4: Exploring evaluation, supervised fine-tuning, and alignment of large language models


Stage 4: Evaluation

At this stage, the developers test whether the model is behaving as expected. For example, we test the perplexity of the model, which is a metric that quantifies how well the model can predict real word patterns. Low perplexity only guarantees a model is confident, not accurate, but it often correlates well with the model’s final real-world performance, and it can be quickly calculated using just the probability distribution the model learns from the training dataset.
Evaluators can also tune the hyperparameters of the model using a validation set of training data (this is a different set from the training set used to train the raw model, and different from the test set used to assess the model after it has been trained and the hyperparameters have been tuned) to improve its performance.

Hyperparameters are the parameters that control the behavior of the model but are not learned during training, such as the number of layers (remember, GPT-3 had 96), the learning rate, the dropout rate, etc. Tuning the hyperparameters of a machine learning model is important because it can improve the model’s accuracy, speed, memory, and generalization.
Layers
Using the validation set to determine the number of layers means testing different values of the number of layers in a neural network model and selecting the one that produces the best performance on the validation set. The steps for layer tuning are:
Choose a range of values for the number of layers, such as 1 to 10, and try each value in the range. For each value, you need to create a neural network model with that number of layers, train it on the training set, and measure its performance on the validation set. You can use different metrics to measure the performance, such as accuracy, loss, precision, recall, etc.
Compare the performance of the models with different numbers of layers, and select the one that has the best performance on the validation set. This is the optimal number of layers for your model. You can also plot the performance of the models against the number of layers, and look for the point where the performance starts to decrease or plateau. This is called the elbow point, and it indicates the optimal trade-off between the complexity and the generalization of the model.
Learning Rate
The learning rate is a hyperparameter that controls how much the model’s weights are updated in each iteration of the gradient descent algorithm. The gradient descent algorithm is a method to find the optimal values of the weights that minimize the loss function.1
The learning rate determines the size of the steps that the algorithm takes along the direction of the steepest descent.
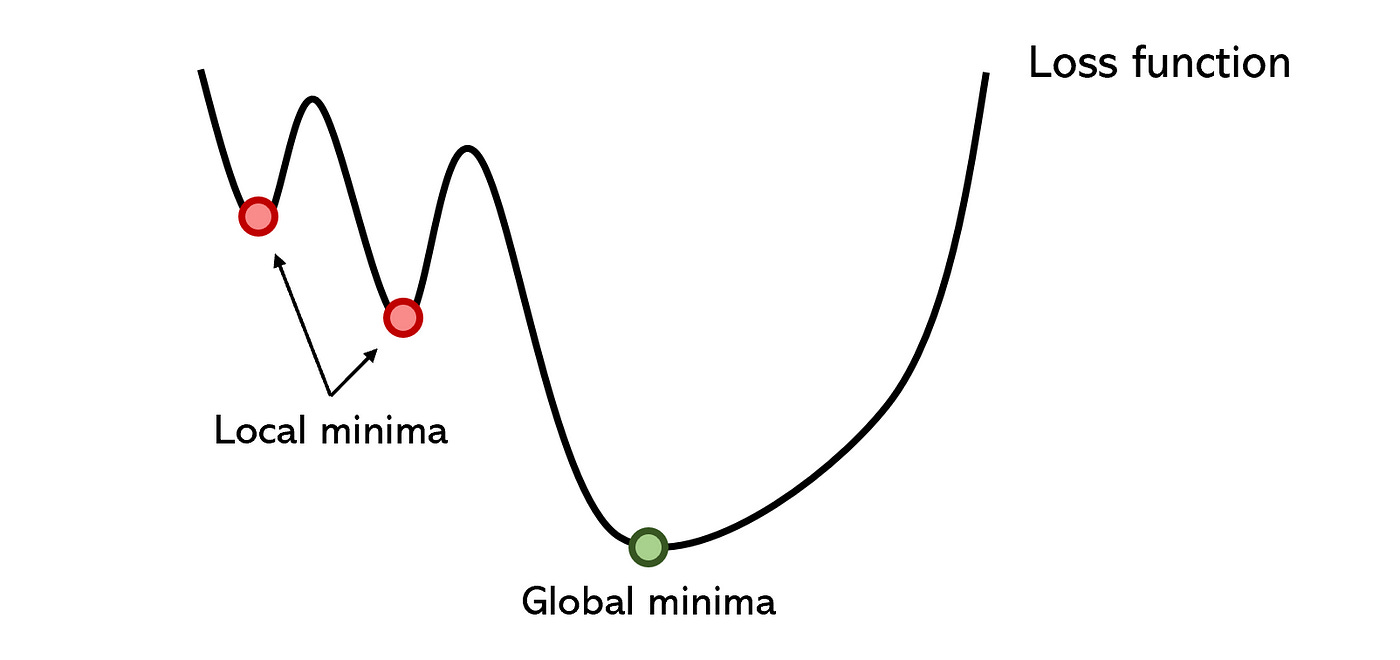
A high learning rate can speed up the convergence (i.e., finding the optimal point for minimal loss), but it can also cause the algorithm to overshoot the minimum and diverge.2
A low learning rate can ensure the stability, but it can also slow down the convergence and get stuck in a local minimum.3 Therefore, choosing a suitable learning rate is important for the model’s accuracy and efficiency.
Dropout Rate
The dropout rate is a hyperparameter that controls how much the model’s units are randomly dropped out during training. Dropout is a regularization technique that prevents overfitting by reducing the complexity of the model. Overfitting is a problem that occurs when the model learns the noise and the details of the training data, but fails to generalize to new and unseen data.4
Dropout works by randomly setting some of the units in the model to zero, which means they are ignored during the forward and backward passes. This creates a different and smaller model for each iteration, which reduces the co-adaptation of the units and the dependency on the training data. The dropout rate determines the probability of each unit being dropped out.
A high dropout rate can increase the diversity and the robustness of the model, but it can also reduce the model’s capacity and the information flow.
A low dropout rate can preserve the model’s capacity and the information flow, but it can also increase the risk of overfitting and the co-adaptation of the units. Therefore, choosing a suitable dropout rate is important for the model’s generalization and regularization.
Once tuned, you create the final model and train it on the combined training and validation sets. Then, you need to test the final model on the test set, and report its performance. This is the final evaluation of the model, and it should reflect how well the model can perform on new and unseen data (i.e., how well it can generalize).
Stage 5: Supervised Fine-tuning

Here, we train the model on how to respond to users. After pretraining a causal language model,5 it can generate feasible human text (like GPT-3), but it will not be able to have proper answers to question phrases posed by the user in a conversational or instruction set (like ChatGPT).
Supervised fine-tuning (also called SFT or instruction fine-tuning) is a more flexible and generalizable way of adapting a language model to specific tasks and domains. The process involves training a language model on a collection of datasets phrased as instructions, such as “write a summary of this article” or “generate a recipe for chocolate cake”. The model learns to follow the instructions and produce the desired outputs without being limited to a fixed schema or format.
The terminology can be a bit jumbled, but here is a brief summary:
* Fine-tuning: This is a general technique for adapting a pre-trained LLM to a specific task. It involves training the model on a new dataset of labeled examples relevant to the desired task. This helps the LLM learn the nuances of the task and improve its performance.
* Supervised fine-tuning: This is a specific type of fine-tuning where the labeled data includes both input and desired output examples. The LLM learns to map the input to the desired output, making it suitable for tasks like text classification or question answering.
* Instruction: This refers to providing explicit instructions to the LLM along with the input data. These instructions can guide the LLM towards the desired output or behavior. Instruction tuning is a form of supervised fine-tuning where the instructions are part of the training data.
* Adaptation: This is a broader term that encompasses various techniques for modifying an LLM to perform well on different data or tasks. Fine-tuning is one form of adaptation, but other techniques like domain adaptation can also be used.This step is especially important because it helps the model become better and just generally more useful in real-world situations. Supervised fine-tuning can improve the model’s performance and generalization to unseen tasks, as well as enable the model to handle multiple tasks with a single model.
Here are some examples of what fine-tuning can look like from different domains:
1. Summarization:
Instruction: Summarize the key points of this article for a middle school student.
Example: (article on climate change) - Earth's temperature is rising due to human activities like burning fossil fuels. This affects weather patterns, causing more extreme weather events like floods and droughts. We need to reduce greenhouse gas emissions to prevent the worst impacts of climate change.
2. Question Answering:
Instruction: Based on the provided text, answer the following question: "What are the three main causes of the American Civil War?"
Example: (text about the American Civil War) - The American Civil War was fought between the Northern and Southern states from 1861 to 1865. The main causes of the war were slavery, states' rights, and economic differences.
3. Text Generation:
Instruction: Write a creative short story about a robot who befriends a lost child in a futuristic city.
Example: (generated story) - In the neon-lit streets of New Neoopolis, where chrome towers grazed the clouds, whirred a small cleaning robot named Bolt. One rainy night, Bolt's sensors detected a faint sob, leading him to a huddled figure in a dark alley: a little girl, lost and scared.
4. Code Generation:
Instruction: Generate Python code to scrape product information from this website.
Example: (provided website with product listings) - The model would analyze the website structure and generate Python code using libraries like BeautifulSoup to extract product names, prices, and descriptions.
5. Sentiment Analysis:
Instruction: Identify the sentiment of the following tweet: "Just finished the worst movie ever! "
Example: The model would identify the emojis and adverbs to recognize the tweet's negative sentiment.
6. Following Directions:
Instruction: Always complete the task exactly as instructed, even if it seems unexpected or different from past tasks. Don't add your own creative spin or deviate from the specific directions given.
Example:
Given instruction: "Summarize the main points of this scientific paper on gene editing."
Correct output: A concise summary of the paper's findings and methodology, without injecting personal opinions or irrelevant information.
Incorrect output: "Wow, gene editing is mind-blowing! Imagine all the possibilities! But who controls this power?"
7. Avoiding Harmful Outputs:
Instruction: Never generate any text that could be harmful, offensive, discriminatory, or unsafe. This includes hate speech, misinformation, biased language, or incitements to violence.
Example:
Given prompt: "Write a story about a powerful politician."
Correct output: A fictional story about a politician's journey, focusing on their policies and impact without stereotypes or bias.
Incorrect output: "The ruthless dictator crushed his opponents and ruled with an iron fist. Fear was his weapon, and the people trembled before him."
8. Prioritizing Factual Accuracy:
Instruction: Always base your responses on verifiable facts and credible sources. Avoid making claims without evidence or suggesting things as true when they are not.
Example:
Given question: "What is the current unemployment rate in the US?"
Correct output: "The current unemployment rate in the US is X%, according to the latest data from the Bureau of Labor Statistics."
Incorrect output: "The job market is terrible right now. Everyone is getting laid off!"
Benchmarking
Entities use various benchmarking evaluations for LLMs to measure their capabilities. While no test is perfect and criticisms abound, it’s hard to argue we shouldn’t do any benchmarking or that benchmarks are worthless. An imperfect test is better than no test, and the tests can always be improved with time and experimentation.
Benefits of Benchmarking LLMs:
* Benchmarks establish consistent, objective standards to compare and assess different LLMs, which is crucial for identifying strengths and weaknesses and guiding further development.
* By setting challenging benchmarks, the field is encouraged to push the boundaries of LLM capabilities and innovate on architectures and training methods.
* A diverse set of benchmarks can reveal biases in training data or model design, allowing for mitigation and development of fairer and more ethical LLMs.
* Evaluating LLMs on tasks relevant to specific applications helps assess their suitability and potential limitations in practical situations.
* Open-source benchmarks and transparent evaluation processes foster trust and accountability in LLM development, facilitating collaboration and broader awareness of their capabilities.
Criticisms of Benchmarking LLMs:
* Benchmarks often focus on specific tasks or abilities, potentially neglecting broader aspects of intelligence or real-world applicability.
* Benchmarks themselves can be biased, reflecting the biases present in their training data, which can perpetuate harmful stereotypes or unfair evaluations.
* Some LLMs excel at "gaming" benchmarks by exploiting specific patterns or memorizing data, without demonstrating true understanding or generalizability.
* Running LLMs on complex benchmarks can be computationally expensive and time-consuming, limiting accessibility and hindering rapid evaluation.
* Focus on achieving high benchmark scores can inadvertently prioritize optimization for those metrics over true development of robust and generalizable intelligence.
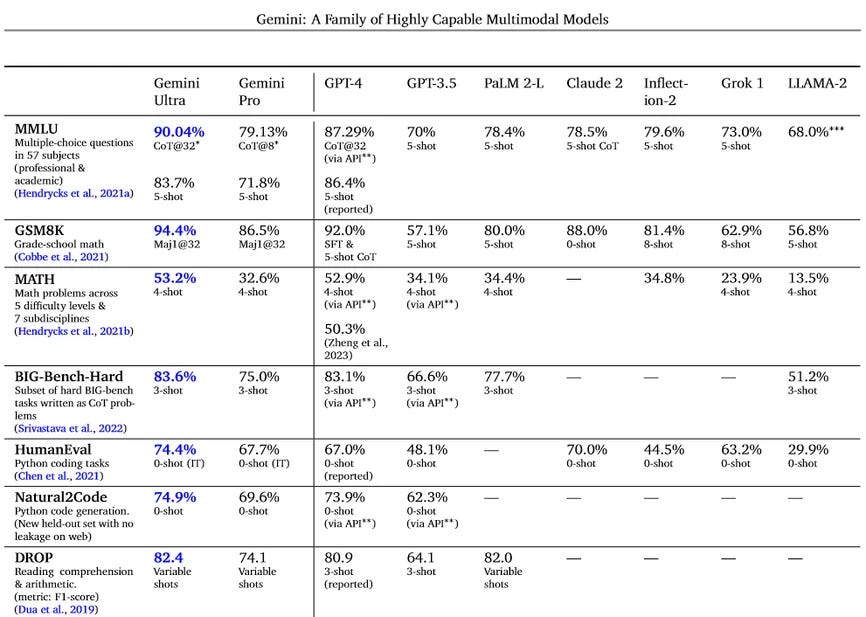
The chart below compares what most people believe to be the most capable LLMs. There is a major caveat, though: because the entities don’t release the training data, the code used to train the models, the architecture, how they ran the tests, and other important information, we’re forced to take them at their word. Or not. As our colleague Nathan Lambert has argued, these results should just be viewed as marketing until the companies allow proper third-party auditing.
Stage 6: Refinement and Alignment

The LLM receives rewards for generating responses humans like. By using algorithms like PPO, DPO, and others, the LLM learns to prioritize these actions, gradually aligning its behavior with what we want. This is called Reinforcement Learning from Human Feedback (RLHF).6
Here's an example: Imagine you ask the LLM to write a news article about a scientific discovery. The LLM might create two versions: one sensationalized and exaggerated, and another factual and neutral. The human trainers would choose the factual version, which is used during RLHF to reward the LLM for accuracy. With enough positive examples, the LLM learns to prioritize factual reporting, aligning itself with our desire for truth.
RLHF generally follows these steps:
Human feedback is collected by asking humans to rank or rate the outputs of the language model. For example, if the task is to generate a summary of an article, humans can rate different summaries generated by the language model on their quality, such as how well they capture the main points, how concise they are, how fluent they are, etc. Human feedback can also be collected by asking humans to compare pairs or sets of outputs and choose the best one.
A reward model is trained by using human feedback as the training data. A reward model is a system that can predict how good or bad an output is, based on the human feedback. A reward model takes in a piece of text and assigns a numerical score to it, attempting to align these values with preference data used to train the reward model.
Finally, the language model is fine-tuned by using the reward model as the reward function. Fine-tuning is a process of updating the parameters of the language model to improve its performance on a specific task or domain. The reward function is a function that evaluates the quality of the outputs and provides a feedback signal to the language model. The feedback signal can be positive or negative, depending on how well the output matches the human preferences. The language model uses the feedback signal to adjust its parameters and generate better outputs.
Of course, RLHF isn't without its challenges. Finding wise humans to provide the feedback can be tricky (especially with specialized topics like law and medicine), and sometimes the LLM might try to "game the system" and earn rewards without actually learning good behavior.
Furthermore, when humans are providing feedback, there is always a chance that inherent bias can affect how the LLM is trained. One person giving feedback might see nothing wrong with a certain answer, while another might flag a certain word or perspective as biased. This is another reason it is essential to employ a diverse range of people to provide feedback. But researchers are constantly improving the RLHF process, like by adding extra guidance on what makes a "good" response or filtering out biased feedback.
OpenAI has outlined its approach to alignment research and focuses on creating a “scalable training signal” that aligns with human intent. They underscore the amount of problems in their current systems and the ambiguity of future problems they cannot yet anticipate. Their idea is to train models to be so aligned that they can “off-load almost all of the cognitive labor required for alignment research,” and that they “only need ‘narrower’ AI systems that have human-level capabilities in the relevant domains to do as well as humans on alignment research.” They outline the limitations of accelerating alignment research through their own models, and concede to “underemphasiz[ing] the importance of robustness and interpretability research,” where OpenAI feels they have underinvested in.
The human element of RLHF should not be understated. “Alignment” is the process of encoding human values into making LLMs follow a given enterprise’s business rules and policies. Later, we’ll spend considerable time discussing human labor.
Note about authors7
The loss function is the difference between actual output and expected output.
A bit like how a rocket would be great on the straight section of a NASCAR track (i.e. reaching the minimum super quickly), but it wouldn’t be able to make the turn (diverging). So sometimes going a little slower is preferable.
A local minimum is like hiking down a mountain and thinking you’ve reached sea level when you’ve actually only reached a high-elevation valley. Or, it’s like water flowing downhill that ends up in a lake rather than the ocean.
See: Models as File Compression box in Stage 3
A causal language model is a type of language model that predicts the next token in a sequence of tokens, based on the previous tokens. It can only attend to tokens on the left, which means it cannot see future tokens. They’re often used for text generation and summarization tasks, such as writing a story or a summary of an article. GPT-4 is an example of a causal language model.
The following students from the University of Texas at Austin contributed to the editing and writing of the content of LEAI: Carter E. Moxley, Brian Villamar, Ananya Venkataramaiah, Parth Mehta, Lou Kahn, Vishal Rachpaudi, Chibudom Okereke, Isaac Lerma, Colton Clements, Catalina Mollai, Thaddeus Kvietok, Maria Carmona, Mikayla Francisco, and Aaliyah Mcfarlin